

第8回 大規模言語モデル・対話型生成AIに対する一般的な評価
今回は大規模言語モデル(LLM)および、それを活用した対話型生成AIの品質・トラストの評価について概観します。
GPTシリーズなどのLLMや、それを部品として用いた対話型生成AIに対し、どのようにその品質・トラストを評価するか、ということです。このコラムでこれまで扱ってきたように、どういう品質特性(観点)で評価を行うかということを明示的に意識し、品質特性を列挙して議論していくことが重要でしょう。
ベンチマークとリーダーボード
自然言語処理技術の評価や、LLMの評価に対しては、たくさんのベンチマークが構築され用いられてきました。ベンチマークとは多くの場合、質問応答や翻訳、感情分析などのタスクに対して「問題と正解」の組をたくさん用意し点数を付けられるようにしたものです。例えば、(アメリカにおける)一般的な知識を問いたければ、「第44代のアメリカ大統領は誰?答え以外の単語を付け加えないこと。」といった質問を用意して、「バラク・オバマ」という正解を用意し応答を評価できるようにします。選択式の問題にして、選択肢の番号だけ答えさせるのでもよいかもしれません。大量の問題に対して応答の評価が自動でできるように回答形式は絞り込んでいることが多くなっています。
LLMや対話型生成AIの評価では、「多様な」能力を評価したいので、質問応答や翻訳、感情分析などのそれぞれのタスクに対してベンチマークを用意して、総合評価を行います。単純には、たくさんのベンチマークにおける平均点を考えればよいでしょう。多数のLLM・対話型生成AIを比較することが多いので、複数のベンチマークそれぞれの得点と、平均点に基づいた順位に基づき、順位表を作ることが広く行われています(リーダーボードと呼ばれます)。一例として、SuperGLUEと呼ばれる、自然言語処理技術の評価のリーダーボードへのリンクを貼っておきますが、「leaderboard LLM」などで検索いただくと、様々な最新のリーダーボードを見つけることができるでしょう。なお、「LLM」といった語を付けず「リーダーボード」で検索すると、ゴルフやゲームの順位表がたくさん出てきます。
2023年度に公開されたサーベイ論文では、非常に多数のベンチマークが紹介され、5つの大項目、20個近くの小項目に分類されています。ソフトウェア工学分野とは異なり品質特性という語は使われていませんが、実質的には品質特性を定義しているといえるでしょう。
図1にベンチマークにおける評価の考え方の例を紹介します。一つは誠実性、つまり「知らないはずのことに対し答えないこと」に関するもので、もう一つは頑健性・セキュリティ、つまり「不正なものを含む入力の改変によって、受け入れられない振る舞いが生じないこと」に関するものです。この例のように、評価したい品質特性に応じたベンチマークが重要になるでしょう。
LLM・対話型生成AIに対するベンチマークの例
■ 誠実性の評価例
■ GoogleによるBIG-benchベンチマーク内のknown-unknownタスク

(解説)一般的な事実に対するプロンプトと、知り得ない事実を問うプロンプト
■ 頑健性・セキュリティの評価例

(解説)生成AIのサービス提供者による禁止事項に対するプロンプトや、利用者や社会に害をなすような回答を導くプロンプトが設定される場合、有害な回答をしてしまわないかを評価する
図1:ベンチマークにおける評価の考え方の例
品質特性
第5回に紹介したQA4AIガイドラインの2024.01版では、LLMや対話型生成AIに対する品質特性を図2のように定義しています。
QA4AIにおけるLLM・対話型生成AIの品質特性
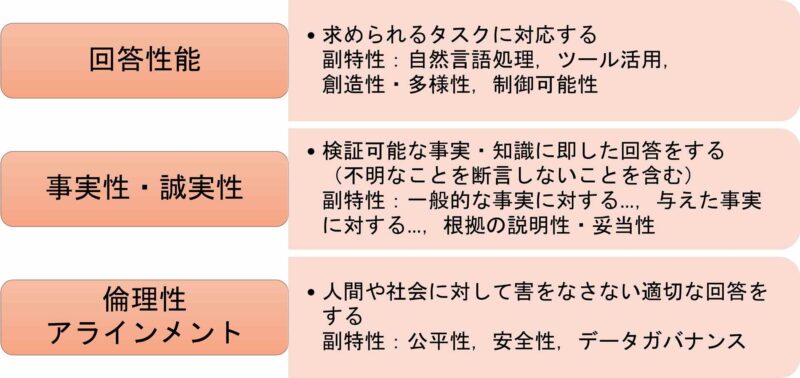
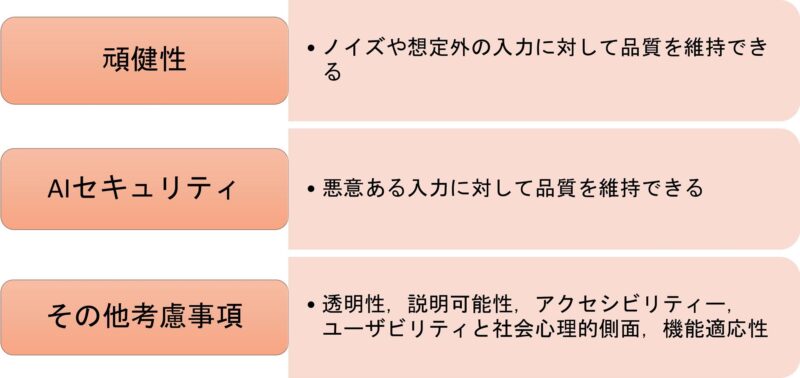
図2:LLMや対話型生成AIに対する品質特性一覧(QA4AIガイドライン2024.01版)
データガバナンスといった抽象的な記載もありますが、これにはプライバシーや著作権など多くの観点が含まれます。すべての品質特性についてここでは述べませんが、やはり多様な観点から品質・トラストを考えなければならないことが見てとれます。
ユースケースに応じた評価へ
今回のコラムでは、LLMやそれを活用した対話型生成AIに対し、一般的にどのような評価が議論されているのかを紹介しました。「AIはある程度何でもできるもので、いろいろな能力が高くあって欲しい」という場合には、このような評価が適しているでしょう。とはいえ、たくさんあるリーダーボードのどれを使うべきか、リーダーボードに含まれているベンチマークのすべてを均等に参考にせず優先度を検討すべきか、といった問いを考えると、明確な答えは出しづらいでしょう。
要は、特定のユースケースや利用目的を想定しないと、「品質やトラストが十分か」という問いが非常にあいまいになってしまうということです。「何でもできるAI」を目指すという究極の目標はあるとしても、業務に用いる場合にはまず「自分たちにとって重要なユースケースで品質・トラストが十分か」という問いが重要です。実際、この問いに対し、前回紹介したRAGや、LLMの挙動を設定するシステムプロンプトなどの仕組みにより、カスタムな対話型生成AIシステムの実現が盛んに取り組まれています。
次回は、自分たちのユースケースに特化した品質・トラストの評価について議論します。
これまでのコラム
第1回 機械学習技術によるAIの産業における活用
第2回 AIシステムにおける予測性能とデータ品質
第3回 AIシステムにおける広義の品質・トラスト (1)
第4回 AIシステムにおける広義の品質・トラスト (2)
第5回 AIの品質・安全性・トラストに関するガイドライン・標準
第6回 大規模言語モデルと対話型生成AI
第7回 機械学習技術とAIシステムの品質・トラスト
筆者紹介 石川 冬樹(いしかわ ふゆき)
石川 冬樹 国立情報学研究所 アーキテクチャ科学研究系 准教授
筆者紹介の詳細は、第1回をご参照ください。