

第1回 機械学習技術によるAIの産業における活用
現在AI(Artificial Intelligence、人工知能)という語が様々な場で飛び交うようになっています。以前は研究室の中の言葉だったかもしれませんが、今では産業応用における多大なポテンシャルを秘めた技術としてとらえられています。
計10回に渡る本コラムでは、産業応用において重要となるAIの品質やトラストについて俯瞰していきます。
本連載の筆者は、石川 冬樹 国立情報学研究所 アーキテクチャ科学研究系 准教授です。
©2024 Fuyuki Ishikawa | National Institute of Informatics (NII)
(本コンテンツの著作権は、石川 冬樹 様に帰属いたします。)
機械学習技術
そもそもAIという語が指すものは非常に広く、「人のように賢いように見える技術」全般をAIと呼ぶこともあり、この場合、時代が進んで当たり前になった技術はAIとよばないようになることもあります。大事なのは、あくまでソフトウェアプロダクト・サービスを構築する技術としての特性や、それに応じた利点や限界を理解することです。現在、2000年代からの第3次AIブームを受け、機械学習技術を用いて実現したソフトウェアをAIと呼ぶことが多くなっています。
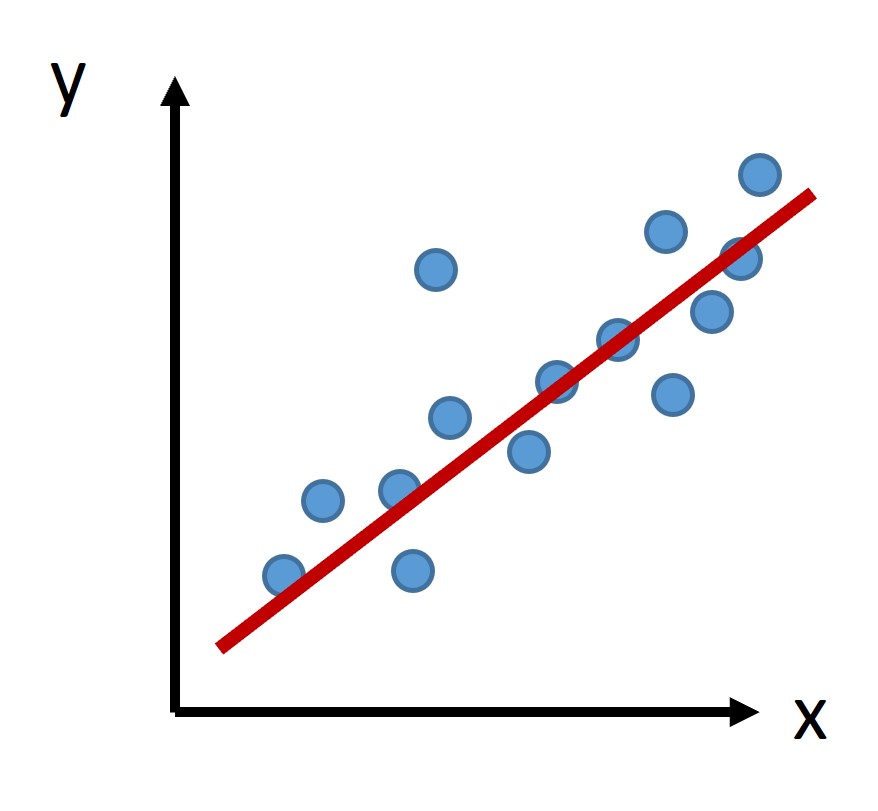
図1上部に機械学習技術の簡単な例として、入力された数値x(ここでは年齢)から、出力として数値y(ここでは給与)を予測する考え方を示しています。
図1 機械学習:簡単な数値予測での例
ある会社での年齢 x のときの給与 y を予測したい
𝑦=𝑎𝑥+𝑏 と表現できると仮定すると,過去のデータと「一番合う」ように 𝑎, 𝑏 を決めれば判定・予測プログラムが作れる!
実際は1次関数(パラメータ2つ)では無理
– 深層ニューラルネットワークでは,何百万,それ以上のパラメータを使う
– 画像や言語に対する性能向上,第3次AIブームの起因
上のグラフにあるように、青い点が過去のデータとしてあったときに、xからyを予測する計算式を作りあげます。ここでは単純に、 y=ax+b という一次式で予測できるとして、過去のデータ(青い点)に対して誤差が少ないように計算式(赤い線)を決めています。実際には、一つの数値の入力で予測することは難しいでしょうし、一次関数、つまり「一定割合で増え続ける、あるいは減り続ける」ことを仮定するのも不適切でしょう。このため、より多くの入力を用い、より複雑な計算式(関係性、傾向)を表現、学習できるような技術を用います。
特に画像や言語など複雑な入力を扱う場合は、基本的には深層ニューラルネットワークという構造を用います。この技術により画像の分類や言語の翻訳など多数のタスクを高精度に実現できるようになっています。このように、深層学習(ディープラーニング)とは、機械学習技術の一つの種類を指す言葉です。
図2には、数値を出力とするのではなく、画像に写っているものがパンダかテナガザルかという
分類カテゴリーを出力とした場合の例を示しています。
図2 機械学習:画像識別での例
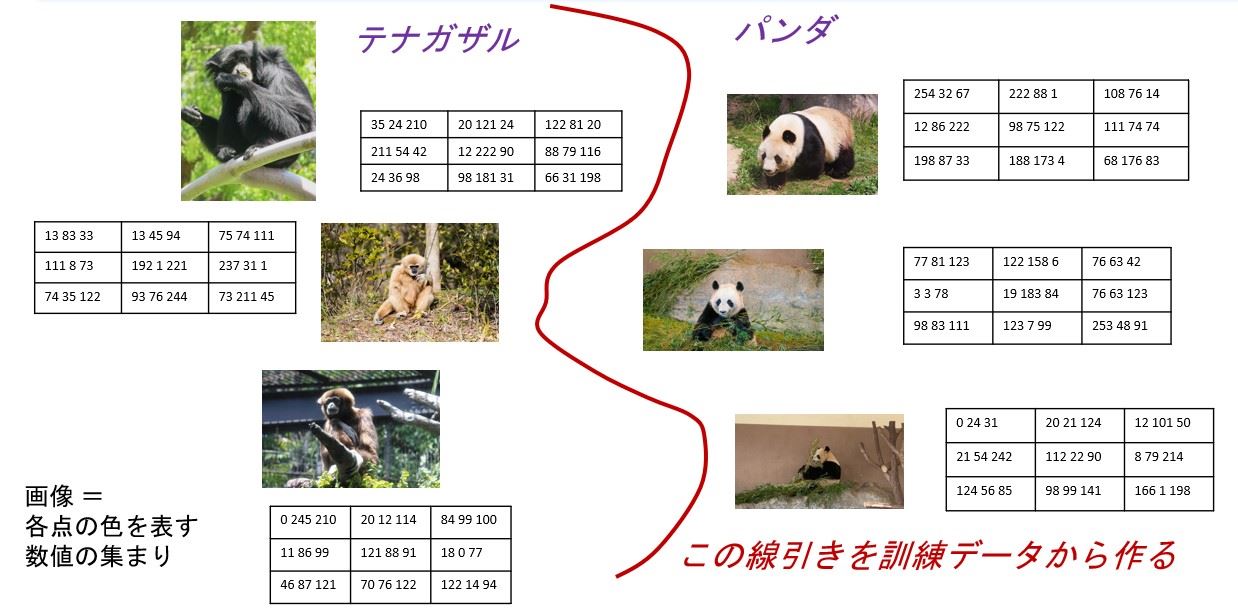
パンダやテナガザルの画像は、計算機上では、画像内の点の色を表す数値の集まりとなります。このような画像が訓練データにたくさんあったときに、やはりデータに基づいて、その間の境界線を表すような計算式を作ることになります。重要な点として、このパンダとテナガザルを見分けるという規則性は、処理ルールとして言葉や数式で人間が書き出すことはできません。訓練データとして大量のデータを用意できれば、機械学習技術により、処理ルールを書き出せないような機能であっても実現できるようになります。
以上で示した二つの例は、入力と出力の正解をペアとしてたくさん訓練データとして与えたときに、そこから出力の求め方を計算式として得る教師あり学習という技術の例です。
他にも、ChatGPTなど対話型生成AIの基となっている言語モデルのように、「何が自然であるか」を学習するようなこともあります(図3)。
図3 言語モデル
言語モデルが学習し,出力できること
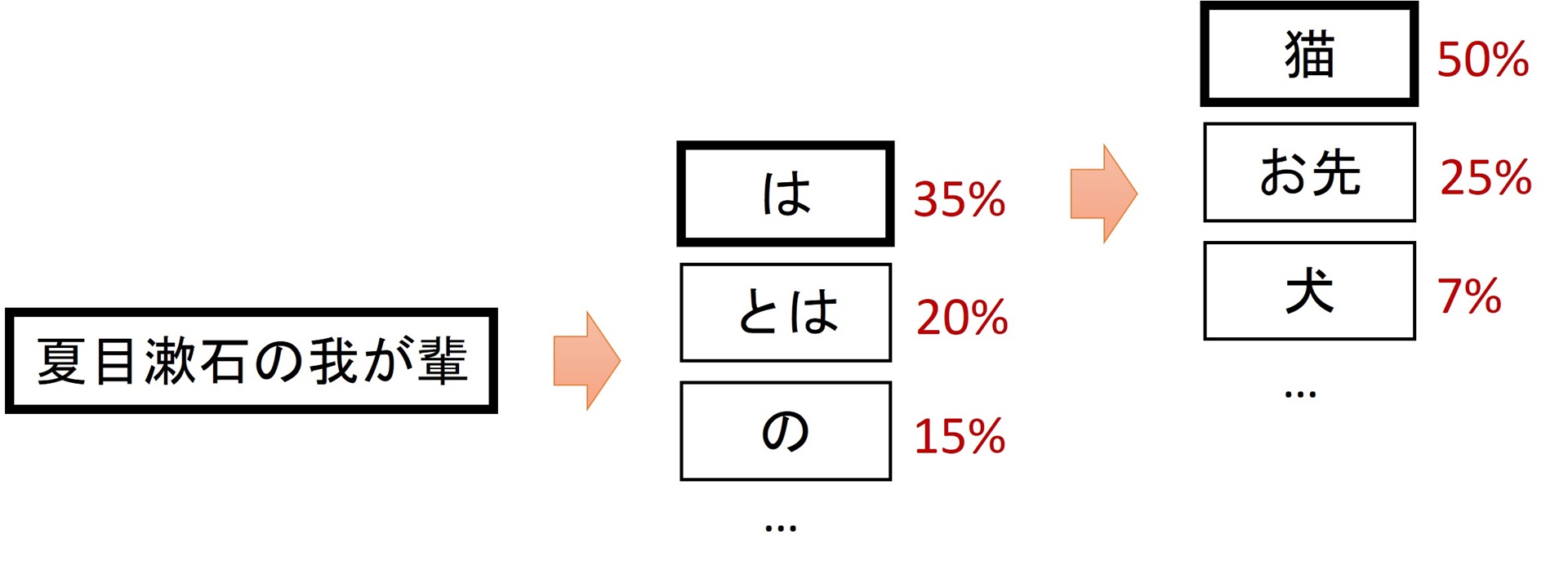
これを大規模学習により極めていくと…

– ChatGPTなどは,「返答が人間にとって望ましいかの判断基準」を 別途学習するなどの多様な工夫が加えられて実用的なものとなっている
機械学習型AIの特性
機械学習技術に基づいたAIに向き合う上では、人間が処理ルールを書き出した仕様書に基づいてソフトウェアを作るのではなく、データに基づいた訓練により処理ルールを得てソフトウェアを作るという開発方法だと考えてもよいでしょう。逆に、何となく「知能」「賢い」と考えてしまうと、何でもできそうな気がしてしまいますが、実際にはそんなことはありません。
例えば、訓練データに含まれていないような入力があるとします。訓練の過程では、そこにはデータがないので、他の部分のデータを基に適当な計算式が構築されます。AIが実行されるときには、どんな入力でも基本的にはその計算式に機械的に当てはめるだけなので、とんでもない誤りをする可能性があります。このことを「外挿はできない」という言い方をしますが、このような特性を把握することが重要です。この特性が理解できれば、「運用において現れるような入力が、開発に用いたデータに含まれているか」の検査や、「訓練データとは異なる入力が来ていないか」という監視が重要となることも把握できます。
機械学習型AIにおける品質・トラスト
機械学習技術は、基本的には正解率を高くすることを大きな目標として取り組まれてきました。つまり、品質評価においては、訓練データとは異なるテストデータを用意し、そのデータに対してどれだけの正解を出せるかということを評価してきました。一方で、製造業や自動運転・運転支援などでは、特定ケースの誤りが大きな事故につながることもあるので、すべての入力に対して平均的によく当たるというだけでは、リスクが低いとはいいがたいことがあります。また前述のように、データの品質を評価するということも必要になりますし、運用監視の考え方も変わってきます。
2017年頃から、「AIの開発」ブームに続き、「AIの品質・トラスト」がブームのごとく盛んに議論されています。国内では、2019年、2020年にそれぞれ、QA4AI、AIQMというAI品質に関するガイドラインが発行されています。2024年現在では、政府からのAI事業者ガイドラインも最近発行され、欧州のAI規制法案が欧州議会で解決されたことも話題になっています。
本コラムではこれから、機械学習技術の特性を確認しながら、AIの品質・トラストに関する原則やアプローチ、動向について紹介していきます。
筆者紹介 石川 冬樹(いしかわ ふゆき)
石川 冬樹 国立情報学研究所 アーキテクチャ科学研究系 准教授

【研究分野】
ソフトウェア工学、自律・スマートシステム、機械学習工学、ソフトウェアテスティング、形式手法、サイバーフィジカルシステム、サービス指向コンピューティング
【略歴】
国立情報学研究所 アーキテクチャ科学研究系准教授、および先端ソフトウェア工学・国際研究センター センター長。 ソフトウェア工学および自律・スマートシステムの研究に従事。 近年は、自動運転やAI システムの品質や安全性に関する技術について、産業界と密に連携して幅広い活動を行っている。 AI 品質保証コンソーシアム 運営委員長。博士(情報理工学)。