

第2回 AIシステムにおける予測性能とデータ品質
今回はAIにおける重要な品質特性である予測性能について学んでいきます。
機械学習やAIの文脈では、性能といえば、出力がどれだけ当たるかということを指しますが、本コラムでは明確化のために予測性能という語を用います。ここでの予測という語は、未来のできごとを当てるという意味ではなく、機械学習技術での出力を指す技術用語です。画像に写っている物体を分類したり、機械に投入すべき薬品量を決定したり、そういった出力全般を予測といいます。機械学習型のAIシステムにおいては、やはり出力がどれだけ当たるかということがまず重要な品質の観点となります。
二値分類における予測性能
具体例として、製品の画像を入力として、傷やゆがみがあるなど不良品を検出するAIシステムを考えてみましょう。出力として、不良品である場合は陽性、そうでない場合は陰性と呼ぶようにします。このようなAIシステムの評価のためには、評価用のデータセットを用意し、そのデータセットにおいてどれだけ正解を出すことができるかを評価します。
このときには図1のような表を書いて考えます。横方向の列には、AIが出した出力が陽性であるか陰性であるかの分類、縦方向の行には、正解が陽性であるか陰性であるかの分類が記され、これらに応じて4つの分類ができています。
例えば右上は、AIは陰性と判断したが正解は陽性であるという見落としのケースが5件あったということを記しています。分類タスクの結果を評価するためのこのような表を混同行列と呼びます。一般の分類タスクでは、写っている物体を「歩行者」「自転車」「自動車」など多数のカテゴリーに分類するので、混同行列は、「歩行者を自転車と間違えるケース」などすべてのカテゴリーのペアを含むより大きなものになります。
図1 機械学習モデルに対する評価
■二値分類での例:陽性か陰性か(例:不良品検出)
混同行列
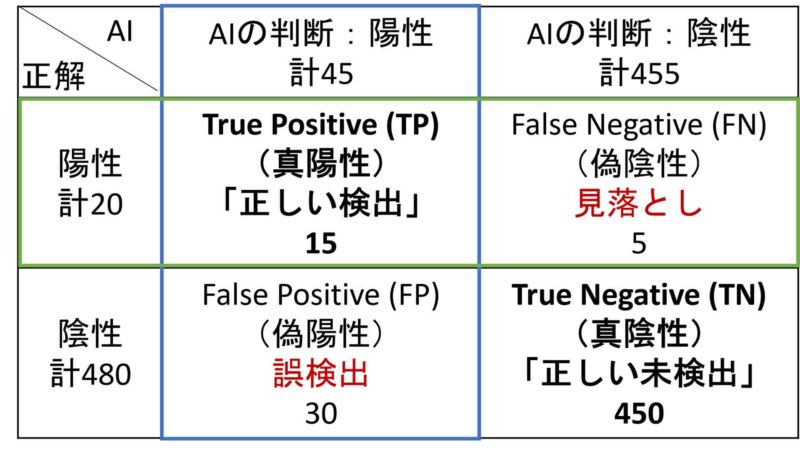
□(青)で囲まれた部分[TP, FP]:AIが出力したものの良し悪し
誤検出が少ないか?(適合率)
□(緑)で囲まれた部分[TP, FN]:検出して欲しいものへの対応度合い
見落としが少ないか?(再現率)
今回の混同行列では左上と右下が正解を当てることができたケースになっており、それらの合計は 15+450=465件となっています。全体が500件なので、正解できた割合(正解率)は 465/500 = 93% となります。
ただし、今回は全体500件のうち陰性が480件と大多数を占めているので、これらを正解できれば正解率は高くなってしまいます。常に「不良品でない」と答えてしまうようなAI(?)があったとしても、正解率は 480/500 = 96% となります。このように、全体を総合的に評価する正解率だけでは、ニーズに合うか・リスクが小さいかといった判断を適切に行えないことがあります。
これに対し図の青い枠では、「AIが出力したものがどれだけ正しく、どれだけ誤検出か」を見ています。ここでは45件中15件正しいので、15/45≒33% という割合が出せます。この指標を適合率と呼びます。一方、図の緑の枠では、「本来検出したいもののうち、どれだけ検出でき、どれだけ見落としているか」を見ています。ここでは20件中15件検出できたので、15/20=75% という割合が出せます。この指標を再現率と呼びます。これらの指標により、誤検出と見落としそれぞれについての評価ができます。
多くの場合これら二つの側面にはトレードオフがあります。「厳しく検査」すれば、誤検出が増え見落としは減ります(適合率が下がり、再現率が上がる)。「甘めに検査し、明らかな不良品のみ検出する」ようなことにすれば、逆が起こります。このどちらをとるか、あるいはバランスをとるのかは、ニーズ・要求、あるいは誤検出や見落としがもたらす影響の大きさによって決まります。不良品検出の場合は、見落とし、つまり不良品が出荷されてしまうことを防ぐことを重視することが多いようです。誤検出があっても、不良品と判断されたものを人間が確認して出荷に回すようなプロセスを採ればよいためです。
なお、もちろん誤検出、見落としがともに非常に少ない完璧なAIに任せられるというのは理想ですが、実際にはそのようなAIを作るのは難しく、上記のように「見落とし防止重視、誤検出許容」といった形でも活用していくことが重要です。
汎化性能
評価に用いるデータセットは、機械学習技術を用いてAIを構築する際の訓練に用いたデータセットとは独立したものを用います。なぜならば、機械学習技術により構築した計算の規則性が、一般性が高いものであることを評価したいからです。このことを、汎化性能が高いといいます。
逆に、「訓練データでよく正解するようにできた」というだけにとどめてしまうと、「同じ問題でしか正解できない丸暗記」のようなことが起きる可能性があります。例えば、訓練データではたまたま、「画像内で斜めになっている部品は不良品である」ことが多いときに、その傾向まで使って正解を出すと、その訓練データではよく正解できるようなことがあるかもしれません。しかし、その傾向は一般的には成り立たないし、傷やゆがみの検出を学習しているわけではありません。
このように訓練データに特化し過ぎた学習のことを過学習と呼びます。なお、逆に、訓練データ内の傾向すらうまく学び取れていないような場合は未学習といいます。
データ品質と予測性能
機械学習型AIの評価に関する基礎知識はまだまだあります。適合率と再現率のどちらをどれだけ優先するかは調整可能なので、いわば「たくさんのAI候補」が得られるわけですが、それらを総合的に評価するAUCという指標もあります。また今回は分類タスクを論じましたが、値の予測を行うタスク(回帰と呼びます)の場合には、誤差の大きさを評価する指標を用います。
いずれにしてもおさえていただきたいのは、機械学習型AIの評価は、データセットに対して相対的に行われるということです。例えば、工場で実際に発生する不良品の傷やゆがみなど様々な種類が含まれていないデータセットで評価を行った場合、求める検出性能が適切に評価できません。評価では性能が高かったものの、実際の運用には「知らない種類の不良品」がたくさん出てきて見落としが多くなるようなことがあるかもしれません。
このように、認識したい対象や問題領域の分析から、データセットの分析と評価を経て、しっかりとAIの評価を行う必要があります。
次回はこの点を踏まえて、AI品質に関する国内のガイドラインに書かれていることを確認していきます。
これまでのコラム
筆者紹介 石川 冬樹(いしかわ ふゆき)
石川 冬樹 国立情報学研究所 アーキテクチャ科学研究系 准教授
筆者紹介の詳細は、第1回をご参照ください。