

第7回 大規模言語モデルの特性とRAG
前回のコラムからは、GPTをはじめとした大規模言語モデル(LLM: Large Language Models)および、それを用いた対話型生成AIに焦点を当てています。今回は、LLMやLLMを組み込んだシステムの品質・トラストを考える前に、LLMならではの応用について考えてみます。
前回のコラムでは、LLMの特徴として、プロンプトと呼ばれる指示入力により様々なタスクを実行可能であることに触れました。これは「各個人がうまく使う」ときには便利で、ある日は翻訳をさせたり、別の日は要約をさせたりということが考えられます。
一方で、業務において活用する場合、人間がLLMに決まったタスクを常に行わせたり、LLMを一部品としてソフトウェアシステムに組み込み特定のタスクを自動化させたりすることもあるでしょう。
このような場合こそ、その業務における役割を踏まえた品質・トラストが重要になってきます。業務で用いる上では、「何でもだいたいそれなりにできる」ことよりも、「必要なタスクについて信頼できる」ことが重要であるということです。
今回は、このような使い方について代表的な例を挙げ、LLMの特性について改めて確認します。
業務知識の問い合わせ・RAG
LLMを業務で用いる場合、「第44代のアメリカ大統領は?」といった問いに答えさせたい訳ではないでしょう。例えば、「自転車事故があった場合に保険金が下りるか?」「このクラスの航空券を1週間前にキャンセルした場合にキャンセル料はどれだけか?」「過去の問い合わせ対応履歴のうち、今回の事例に近いものはどれか?」といった問い合わせが対象となるでしょう。つまり、質問応答を実現したいのは、OpenAIやGoogleがオープンなデータセットから学習させた知識ではなく、業務固有の知識であるということです。すると、ChatGPTなどの対話型生成AIをそのまま使ってしまうと、公開されている最新の業務知識が学習されているかも不確かなほか、ハルシネーション(事実とは異なる回答)の可能性もあり、そもそも公開されていない情報については「常識から推測する」ことしかできません。「特性も何も考えず、何でもAI(LLM)にそのままやらせる」のは当然うまくいかないということです。
それではどうすればよいかというと、業務知識は「生成」するものではないわけですから、「検索」で取得して、それを基に問い合わせの回答を「生成」すれば良い訳です。このようなアプローチをRAG(Retrieval Augmented Generation)と呼びます。
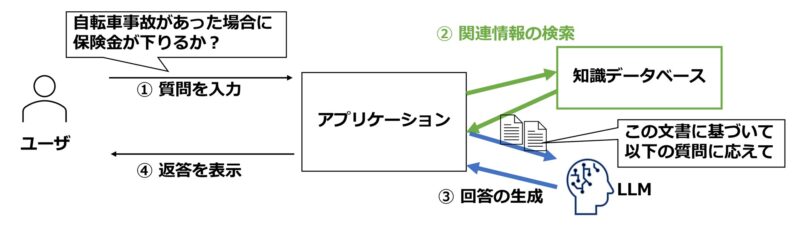
RAGの考え方を図1に示します。問い合わせに対しては、まずそれに関連しそうな情報の検索を行います。例えば、保険に関する規定のうち、自転車事故に関する記載が抜き出されてきます。次にLLMに対し、「この検索結果を基に問い合わせに答えよ」ということで、回答を生成させます。これにより、学習結果に依存せず、最新・固有の業務知識を反映できるほか、ハルシネーションも比較的起きにくくなります。また、途中過程としての検索結果があるので、回答における根拠の説明や、品質評価・改善のための挙動分析も行いやすくなります。
図1:RAG の概念図
RAG (Retrieval-Augmented Generation)
■学習した知識に頼るのではなく、検索結果をまとめさせる
■最新・専門・社内固有の知識を確実に反映させやすい
■回答根拠(=検索結果)も提示できる
ここでぜひ意識していただきたいのは、「検索」と呼ばれるものの実現手段です。LLMの登場以前から、機械学習技術の発展により、自然言語を「うまく」数字の列として表現するベクトル化の技術が発展してきました(そのほか、埋め込み・Embeddingという語を使うこともあります)。似た使われ方をする単語や文章は近い数字の列として表現されるように、ベクトル化の方法はうまく学習されています。ここでの「近い」はベクトル同士の近さで、コサイン類似度と呼ばれる指標について聞いたことがあるかもしれません。
RAGにおいては多くの場合、検索においてもこのベクトル化された単語・文章を扱うことが想定されています。キーワード検索とは異なり、「自転車事故が起きた」と「自転車が衝突した」といった見た目の単語が異なる文章でも、類似しているとして検出することができます。
一方、あくまで類似性に基づく検索なので、「被保険者が20歳未満」に関する問い合わせで、「被保険者がぶつかった人が20歳未満であったため、・・・」といった文章がひっかかるような可能性もあります。厳密、正確な検索を行いたい場合は、検索先の知識データベースを構造化し、問い合わせも内部では厳密なクエリ言語で行うことも想定されます。例えば、情報システムで広く用いられているように、RDB (Relational Database)に対してSQLというクエリ言語を用いれば、表形式のデータについて「年齢が20歳未満のエントリだけすべて抜き出す」ようなことは正確にできます。
さらには、「AとBはRという関係にある」という3点セットをたくさん集めた知識グラフという形式なら、さらに柔軟に多様な情報が厳密に表現、問い合わせできます。例えば、「Aは千代田区に住んでいる」「千代田区は東京都の一部である」という二つの情報から、「Aは東京都に住んでいる」ということも把握することができます。このようなグラフ形式を知識データベースに用いたRAGはGraphRAGと呼ばれ、注目されています。ただし、当然ながら構造化された知識データベースが必要ということですので、求める正確さとコストなどとの兼ね合いになるでしょう。
他の応用
LLMの応用は無数にありますが、ここではLLMの特性・得意不得意に注目していくつかの例を論じます。
GitHub CoPilotに代表されるように、プログラムコードの生成はかなり能力が高く、組織によっては多く活用されているようです。こちらも、社内固有のライブラリなどを扱う場合には、当然うまくいかないので、訓練データを用意してファインチューニング(追加学習)を行わせるか、追加プロンプト・RAGなどで社内固有のライブラリについての知識を都度与えるか、何かしらの施策が必要になります。
また、ソフトウェア工学やWebシステムに関する学術研究では、LLMを用いたログの構造データ化もかなり取り組まれています。今のソフトウェアシステムは様々なライブラリを用いるので、ログの出力形式も一定でないこともあり、少なくとも、ログの出力形式がしっかりと文書化され保守されていないことがあります。
LLMは、いくつかの具体例と正解を教えれば、「ログテキストのうち、どの部分が時間の記載で、どの部分が固定メッセージか、どの部分がエラー番号か」といったことを抽出できます。これにより自動で、CSVファイル・Excelファイルなどの構造化データに変換することができます。そうすると、異常検知や、データマイニングなどの統計分析などはいくらでも自由に行うことができます。この場合も、「何から何までLLMにEnd-to-Endでやらせる」のではなく、構造の厳密な処理がないログテキストの構造化だけをLLMにやらせ、あとは、構造化データを入力とする既存技術を活用し放題という状況につなげています。
まとめ
今回のコラムでは、RAGをはじめとして、LLMの特性を踏まえ、他の技術も用いながら適切に活用するアプローチについて論じました。何となく「AIにやらせる」というのではなく、概念的にでも仕組みや特性を理解することが重要です。次回以降は、LLMやそれを組み込んだシステムの品質・トラストについて論じていきます。
これまでのコラム
第1回 機械学習技術によるAIの産業における活用
第2回 AIシステムにおける予測性能とデータ品質
第3回 AIシステムにおける広義の品質・トラスト (1)
第4回 AIシステムにおける広義の品質・トラスト (2)
第5回 AIの品質・安全性・トラストに関するガイドライン・標準
第6回 大規模言語モデルと対話型生成AI
筆者紹介 石川 冬樹(いしかわ ふゆき)
石川 冬樹 国立情報学研究所 アーキテクチャ科学研究系 准教授
筆者紹介の詳細は、第1回をご参照ください。