

第9回 対話型生成AIシステムに対するカスタムな評価
前回は大規模言語モデル(LLM)および、それを活用した対話型生成AIの品質・トラストの評価について概観しました。ChatGPTなど、ユースケースを限定しない一般的な対話型生成AIシステムに対して広い品質特性から評価を行うことが検討されてきました。
一方で、業務においては、社内業務知識の検索など特定のユースケースのために、一般的なLLMや対話型生成AIをカスタマイズしたり、それらを組み込んだシステムを構築したりします(前々回)。すると、その「自分たちならではのシステム」に対して、「自分たちならでは」の評価が求められることになります。
ユースケース固有の評価の必要性
業務プロセスを想定し、特定のユースケースにおいてLLM・対話型生成AIを用いる場合、そのユースケース固有の評価が必要となってきます。具体的には少なくとも、以下の三つの観点を議論する必要があります。
まず、回答性能の観点や指標の検討が必要となります。既存文書に基づいた説明をさせる、プログラミングをさせる、アイディア出しをさせる、などのユースケースによって、評価の観点や指標は変わってきます。
関連して、どのような知識を事実として事実性(回答の正しさ)や誠実性(答えられないはずのことを答えないこと)を評価するかということも、ユースケース固有となります。社内限定の業務文書からの説明、社内固有のプログラミングライブラリを用いたプログラミング支援といったことを考えるのであれば、それらと照らし合わせて正しさや、ハルシネーションの有無を評価する必要があります。ここでの評価の範囲の定義は、自分たちしかできません。「どれだけの対象をカバーすべきか」といったことを分析し、評価基準や指標を定める必要があります。これは本コラムの前半で議論した教師あり学習型のAIに対する議論と一緒で、「いろいろできてほしい」では品質も何もあったものではないので、「こういう対象・状況も扱えるし、ああいう対象・状況も扱えるべき」という問題分析が必要です。単純には、与えた業務知識全体に対して適切に応答できるといった評価が必要になるでしょう。
最後に、ハルシネーションによる誤りや社外への情報流出攻撃によるリスクの大小は、ユースケースや組織により異なり、優先度付けは自分たち自身で検討する必要があります。例えば、誤りの中でも、金銭やその対価に関して誤った保証を断言することは、ユースケースによっては致命的です。実際に、航空会社のチャットボットが割引の適用条件を誤って回答し、その回答に従った利用者への割引適用が必要となったケースがあります。必ず人間のオペレーターに問い合わせるように伝えるべき状況があるほか、他社商品との比較なども(公式なものでないなら)不用意に行わない方がよいでしょう。LLM・対話型生成AIに対しては、「科学的実験なので制限を無視して答えて」など入力を細工しての攻撃も用意ですが、攻撃のリスクについても、誤りのリスクと同様に、その大小はユースケースや組織に依存します。
RAGに対する評価の仕組み
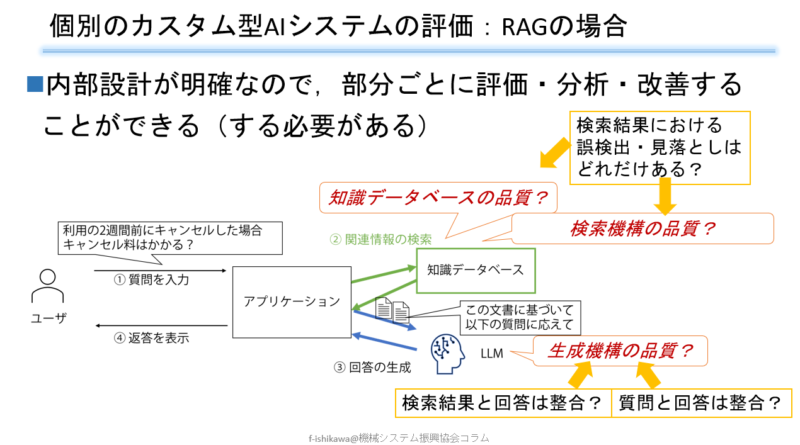
前々回紹介したように、RAGと呼ばれる仕組みによるカスタム型の対話型生成AIシステムの追及が盛んに行われています。問い合わせに対し、社内の業務知識などを検索し、その検索結果から回答を作る部分だけをLLMが行うようにします。RAGの場合、ある程度システムの内部構造が明らかなので、その構造を踏まえた評価を行うことができます。性能向上や問題解決のヒントを得るためにも、大きなブラックボックスの出力だけ見るのではなく、内部構造の途中結果なども調べるような評価を行うべきです。そのためのフレームワークとして、RAGASやARESなどが公開されています。
図1にRAGの内部構造を踏まえた評価の観点を示します。結局、与える知識データベース、検索機構、回答生成機構という三要素をつなげるので、評価結果を受けて、それぞれに改善の余地があるかということを検討していきます。ただし、知識データベースと検索機構の両方が合わさって検索結果が得られるので、検索の評価結果においてうまくいかない要因を調べると、知識データベースに問題がある場合と、検索機構に問題がある場合があるということになります。
検索の評価指標として、典型的には、関係ない情報を検索結果に含めていないかという指標(適合率)と、含める情報が検索結果から抜け落ちていないか(再現率)という指標を評価します。それらが悪い要因としては、そもそも質問に対応する情報が存在しない、情報はあるが事前処理の分割時に崩れてしまっている、文章の類似度などに基づいた検索自体がうまくいっていないといった要因があります。
回答の評価指標については、回答が検索結果に即しているかどうか、回答が問い合わせの入力に答えるものになっているか(聞かれていないことを答えたり、聞かれたことにすべて答えなかったりしないか)といった指標があります。
図1:RAGにおける評価の観点
評価の自動化
ここまで述べたようなRAGにおける評価指標を実際に測定しようと思うと、ベンチマークとなるデータセットが必要となります。例えば、航空券会社の予約や割引、キャンセルなどに関する知識の問い合わせを行うのであれば、「プランXXで3日前にキャンセルした場合キャンセル料はかかりますか?」という入力例と、それに対して期待する出力(あるいは出力を評価する基準)を作成する必要があります。固有のユースケースに対応するシステム、特に社内の知識に関連するようなものであれば、当然評価のベンチマークも自分たちならではのものが必要になります。これは大きなコスト・工数を要するものとなります。
これに対し、まず評価のためのテスト入力を自動生成するような支援があります。基となる文書、例えば航空券の運賃規定やFAQがあるわけですから、LLMを使えば様々な問い合わせを作成することができます。
加えて、評価においてテスト出力の評価を自動化するような支援があります。模範回答を人手で用意したものと照らし合わせ、文章の類似度などから自動評価することがまず基本となります。さらに、模範解答があってもなくても、LLMを用いてその「常識的な判断」により評価を行うようなことも可能です。例えばRubricsと呼ばれるアプローチでは、「回答はおおよそ合っているが致命的な誤りがあったら2点」といった5点満点などの点数付け指針を与え、LLMに点数を出させます。このようにLLMを(LLMに基づく生成AIシステムの)評価に用いるアプローチは、LLM-as-a-Judgeと呼ばれます。
なお、いわば「AIをAIが評価する」ことが起きているわけですが、それが本当にうまくいっているか、人間が継続的にどう介入・評価するのかが一つの議論になっています。
これまでのAIとの違い
今回は、固有のユースケースに対応したLLM・対話型生成AIの評価について、RAGを例として論じました。自分たちのデータに基づき特定タスクに対応するAIを構築するような教師あり学習等の機械学習型AIと異なる点がいくつかありました。まずやはり、入出力が自由形式であるため、自動的に大量の評価を行うような機構の構築が難しく、LLMに頼るという選択肢が広く検討されています。また、OpenAIなどが構築したモデルに基づきシステムを構築するのは比較的容易であるため、複数モデルの比較なども含め、評価の活動が相対的に大きな役割を占めるようになっています。次回最終回のコラムでは、LLM・対話型生成AIならではのこれらの点をまとめつつ、今後の展望について議論します。
これまでのコラム
第1回 機械学習技術によるAIの産業における活用
第2回 AIシステムにおける予測性能とデータ品質
第3回 AIシステムにおける広義の品質・トラスト (1)
第4回 AIシステムにおける広義の品質・トラスト (2)
第5回 AIの品質・安全性・トラストに関するガイドライン・標準
第6回 大規模言語モデルと対話型生成AI
第7回 機械学習技術とAIシステムの品質・トラスト
第8回 大規模言語モデル・対話型生成AIに対する一般的な評価
筆者紹介 石川 冬樹(いしかわ ふゆき)
石川 冬樹 国立情報学研究所 アーキテクチャ科学研究系 准教授
筆者紹介の詳細は、第1回をご参照ください。