

第10回 今後に向けて
本コラムではこれまで9回に分けてAIシステムの品質に対する考え方、アプローチについて俯瞰してきました。最終回となる今回は、全体に共通する考え方と今後の展望について議論していきます。
難しさの一つの根源:不確かさ
これまでAIシステムに対する品質特性、すなわち評価すべき観点と、その評価アプローチについて示してきました。従来のソフトウェアシステムにおいても、信頼性、時間性能、保守性などの品質特性があり、品質保証の活動が広くなされてきました。
AIシステムについては公平性、説明可能性など固有の品質特性があるものの、同じようなプロセスや枠組みでそれらを扱っていけばよいのでしょうか。この点については多様な意見があるかもしれませんが、必ず意識すべき点の一つは不確かさです。具体的には、以下のような不確かさがあります。まず、対象とするタスクに対してどれだけの性能、例えば不良品検出の見落としや誤検出の少なさが達成できるかは、理論的・経験的な予測が難しく、実際に構築して試してみるまでわかりません。加えて、AIシステムとしての性能が高いことが、ビジネス上あるいは人間・社会に対してどれだけの効果があるかの直接的なつながりが把握しづらい、短期的には評価しづらいこともあります。
AIシステムは基本的に不完全、つまり間違えることがあるものもあるため、「85%当たる」といった評価から受け入れや活用の意思決定を行う必要があります。不良品検出や広告推薦、株価予測などでは、AIシステムの出力の正否と経済的な収入・支出が直結するかもしれません。業務知識に対する検索や質問応答の補助、心理カウンセリングなどの効果は定量化しづらいかもしれませんし、自動運転による事故の低減など統計的に結論を出すためには長期の調査が必要になることもあります。効果あるいは費用対効果の見積もりに高い不確かさがあるといえるでしょう。
次に、性能を上げるための技術やパラメーター設定、プロンプトなどは、ある程度の指針はあるものの、複数の指針のどれが適しているか、コストをかけてどれだけ性能が上がるかといった点の予測は困難です。具体的には、訓練の方法を定めるモデル(ニューラルネットワークの設計など)や、ハイパーパラメーターの設定(学習により設定されるパラメーターではなく、学習の方法などを定める設計パラメーターのこと)、LLM・大規模言語に与えるプロンプトなどについて、複数を試行し評価する必要があります。設計の適切さ・最適さの見積もり、あるいはその根拠となるような技術的特性について高い不確かさがあります。
大規模言語モデル(LLM)・対話型生成AIについては、上記のような不確かさが高くなるとともに、異なる種類の不確かさも非常に高くなっています。大規模言語モデル(LLM)・対話型生成AIにおける評価のライフサイクルにおける上記のような不確かさや変化の影響を図1にまとめます。
図の左側ではシステム構築の流れを示し、右側ではそれに対する評価の流れを示しています。LLMの場合は、左下にあるように多くの場合他者が構築したモデルを利用し、プロンプトなどの利用方式の設計のみを行うことになります。左上にあるように、モデルはシステム全体の一部に過ぎず、入出力をチェックするような安全機構や、他のLLMや従来ソフトウェア部品と連携するでしょう。これに対し、右側の下にあるようにLLM単位での評価、そして真ん中にあるようにシステム全体での評価が行われます。さらに右上にあるように、実際に利用してみる中でも評価がなされます。一方、システム構築時に「万全」とするのが難しい不確かさは、以下の通りです。一点は左下にあるように、モデルの更新が速く、予測・制御ができないことがあります。また右側にあるように、実世界のあいまいなタスクを扱うために要求・評価基準があいまい・不完全になりがちで、運用後に追加や修正が発生することが原則となってきます。
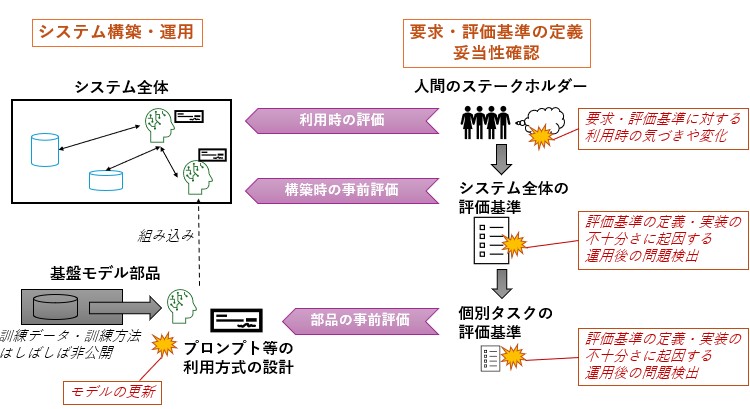
第一に、入出力として自由なテキスト形式を扱う場合、どのような入力がなされうるか、そしてどのような「問題ある出力」が想定されるか、の検討が網羅的であることは非常に難しくなります。評価基準が変わっていくことも一つ重要な点として、 “Criteria Drift” という言葉も挙がっています。品質評価の十分性や妥当性に対する不確かさが非常に高いといえます。
第二に、大規模言語モデル(LLM)・対話型生成AIについては、大企業によるモデルの更新、それに伴う社会の変化が非常に激しくなっています。コストをかけて性能を高める工夫をカスタムで組み立てても、利用するモデルやそのバージョンが変わるとその工夫の効果が低くなってしまったり、そもそもモデルの性能向上や新たなサービスの登場により工夫が要らなくなったりする可能性があります。追求した技術的アプローチや実現したシステムの優位性や妥当性に関する不確かさが高いといえます。
評価と改善のサイクルに向けて
何か不確かなことがあった場合、綿密な分析を行い、その不確かさを解消することで、その影響によるリスクを低減することが望ましいでしょう。しかし、それを理論的な分析で行うことが難しいということが、上述したポイントとなります。このため、本コラムで扱ってきた機械学習型AIシステムに対しては、迅速に試して評価すること、そして「早く失敗する」ことで不確かさを取り除いていくこと、そして不確かさや不完全さがあっても「ポイント」を押さえて活用することの方が重要となります。従来のソフトウェアシステムについては、開発と運用を断絶せず一体化し、運用を通した評価と改善のサイクルを回すことの重要性がDevOps(Development+Operationの意)といったキーワードで議論されてきましたが、似たような考え方が重要となります。
自分たちで収集したデータを用いて訓練を行うような機械学習型AIシステムの場合、POC (Proof-of-Concept) という段階にて、「お試し」のモデルを構築して性能を評価し、実現可能性に対する不確かさを低減し、ビジネスに有効であるかどうかという仮説を検証して進めていきます。さらに、訓練データと運用時に現れるデータとのギャップなどの不確かさがあるため、運用時にも新しいデータや性能に対する評価を継続的に行っていきます(MLOps:Machine Learning Operations)。
LLM・大規模言語モデルについては、大半の場合、人間が行うのがプロンプト調整と評価が中心になるため、それらを反復していくことになります。プロンプト調整は比較的コストが小さく、求められる技術的な専門知識も少ないため、システムの構築・試用は盛んに行われています。それに対し、自由な入出力形式や、あいまいな「良さ」の基準に対する評価が難しいことから、評価の活動や、評価結果に基づく改善の活動はまだ限定的かもしれません(LLMOps:Large Language Models Operations)。
LLM・大規模言語モデルについては、まだまだ技術的な進展は続いていくでしょう。例えば本コラムでは、複数の異なる専門性を持つLLMを連動させて複雑なタスクを実現するワークフロー形式のシステムや、その際に実現方法を自律的に定めるエージェント形式のシステムについては扱っていません。これらについても、様々な支援環境が整備されており、何かのタスクを(半)自動化し支援するようなシステム作ってみる・試してみることは非常に容易になってきています。一方でやはり、評価の活動や、評価結果に基づく改善の活動、それらのサイクルには至れていない組織が大多数かと思います。
著者は、「それなりに動くものができた」状態から、「ビジネス上の価値や問題解決の程度を評価し、それらの観点で重要な点に注力し改善をしていくようなサイクルが安定して実施できる」ことが、「品質」「トラスト」として最も重要なことだと考えています。非常に変化が激しい世界ですが、本コラムや関連するコミュニティを通した協働により、そのような品質・トラストを高めていけるような活動を広げていければと考えています。
これまでのコラム
第1回 機械学習技術によるAIの産業における活用
第2回 AIシステムにおける予測性能とデータ品質
第3回 AIシステムにおける広義の品質・トラスト (1)
第4回 AIシステムにおける広義の品質・トラスト (2)
第5回 AIの品質・安全性・トラストに関するガイドライン・標準
第6回 大規模言語モデルと対話型生成AI
第7回 機械学習技術とAIシステムの品質・トラスト
第8回 大規模言語モデル・対話型生成AIに対する一般的な評価
第9回 対話型生成AIシステムに対するカスタムな評価
筆者紹介 石川 冬樹(いしかわ ふゆき)
石川 冬樹 国立情報学研究所 アーキテクチャ科学研究系 准教授
筆者紹介の詳細は、第1回をご参照ください。