

生成AI活用に向けた企業内データの整備検討フォーラム
~ 生成AIを使って企業の変革・発展をいかに進めるのか ~
当協会では、2024年7月に「生成AI活用に向けた企業内データの整備検討フォーラム」(委員長:武田 英明 国立情報学研究所 教授)を立ち上げ、生成AI活用に向けた企業内データの整備に係る現状と課題と今後の取組の方向性について、5回にわたり有識者からの講演を行うとともに、参加委員を交えて議論し、2025年3月末に報告書をまとめました。
以下、報告書のサマリーを紹介いたします。
生成AI活用に向けた企業内データの整備検討フォーラム 委員
| 氏名 | 所属 | 役職 |
| [委員長] 武田 英明 | 国立情報学研究所 情報学プリンシプル研究系 | 教授 |
| 石川 冬樹 | 国立情報学研究所 先端ソフトウェア工学・国際研究センター | センター長 |
| 石切 聡 | アズビル株式会社 業務システム部 | 副部長 |
| 岡田 忠 | 独立行政法人 情報処理推進機構 デジタル基盤センター デジタルエンジニアリング部 | エキスパート |
| 佐藤 雅彦 | 株式会社リコー デジタル戦略部 データマネジメントセンター デジタル基盤開発室 | エキスパート |
| 田中 紀子 | 株式会社 荏原製作所 データストラテジーチーム データエンジニアリンググループ / 戦略企画グループ | グループリーダー |
| 廣岡 司 | 旭化成株式会社 デジタル共創本部 スマートファクトリー推進センター IoT推進部 IoT推進グループ | 課長 |
| 松下 雄史 | 旭化成株式会社 生産技術本部 生産技術センター 産機システム技術部 | エキスパート |
| 福田 賢一郎 | 国立研究開発法人 産業技術総合研究所 人工知能研究センター データ知識融合研究チーム | 研究チーム長 |
| 前川 徹 | 東京通信大学 情報マネジメント学部 | 教授 |
| 宮本 淳一 | 株式会社PFU 業務革新センター 業務デジタライズ推進室 | 室長 |
| 村上 存 | 東京大学 大学院工学系研究科 機械工学専攻 | 教授 |
| 相澤 徹 | 一般財団法人 機械システム振興協会 | 専務理事 |
| [オブザーバ]中里 克久 | 独立行政法人 情報処理推進機構 デジタル基盤センター デジタルエンジニアリング部 AI システムグループ / AIセーフティ・インスティテュート |

1. 概要
これまで我が国の多くの企業では、データ重視の経営を実行するため、マスターデータ管理(MDM)の観点から、業務プロセスの可視化、データ基盤 の整備を進めてきた。こうした取組を実施した企業では、各拠点や事業部門でばらばらであったデータ形式の共通化、異なるシステム間でのデータ交換、アクセス権の統制やデータのメンテナンスなどにより、社内におけるデータ活用が図られ、経営層がリアルタイムで社内状況をデータで把握することが可能となっている。
こうした取組が既に進んでいる企業では、進化が著しい生成AIをさらに活用すれば、より高度な分析を簡便に行うことができるようになる。
一方で、生成AIをビジネスの現場で活用したいと考えている企業の中には、業務プロセスの可視化、データ基盤の整備の段階でつまずいている企業も少なくない。
本フォーラムでは、進展する技術や政府・産業界の動向の中で、日本企業が実際に生成AIによるデータ活用を進める中で抱えている課題について議論し、日本企業が取り組むべき方向性や今後さらに検討すべき点を明らかにする。
2. 生成AI活用に向けた企業内データの整備に関する課題
独立行政法人 情報処理推進機構(IPA)が2023年2月に公表した「DX白書2023」によれば、日本企業におけるデータ活用は米国に比べ、取組が遅れている状況にある。また、昨今、技術の進化が著しい生成AI活用については、日本企業は欧米企業に比べ、高度なデータ分析への取組や生成AIの導入についても遅れを取っている。
この点を打破するためには、経営層が企業内データ整備に対するガバナンスの重要性を十分理解し、それにコミットメントしていくことが必要であることは言うまでもないが、その際、自社のデータ活用の現状レベルを把握した上で、何のために取り組むのか、どのような品質レベルを目指すのか、全社的にどうまとめていくのかといった点まで踏み込んだ具体的なマネジメントが求められる。
海外とのデータ利活用に関する調査比較でみると(【図1】参照)、残念なことに、アメリカと日本を比較すると、ITに 見識がある役員が、我が国ではアメリカに比べ5割に満たない。実際のところ日本では、役員がITに関して理解ができない、もしくは見識がないためになかなか先に進まないことがある。
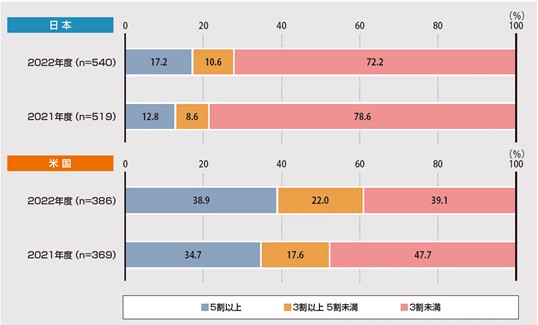
【出典】「DX白書2023」(IPA、2023年2月公表)
また、生成AI活用の大きなメリットがある一方、企業内データの活用に際しては、AIによる学習の基となる入力データの品質が、生成AIの出力に大きな影響を及ぼす点に留意する必要がある。特に、生成AIが出力するデータの品質は、生成AIの学習に利用されるデータや、RAG(Retrieval-Augmented Generation)を構成するデータの形式と量に依存することを理解し、利用目的に応じて、出力データに要求する品質レベルに対して、用意する入力データの形式がどの程度の影響を及ぼすかを精査しつつ、データ基盤の整備に取り組む必要がある。
こうした点を踏まえ、本フォーラムでは、具体的に以下のとおり、論点と課題を設定し、項目ごとに議論を深めた。
【論点と課題】
【論点1】 業務プロセスの可視化、データ基盤の整備が進んでいる企業については、今後、生成AIを積極的に導入する上で、現在のデータ基盤がどのような問題点を持っているのか明確にする。
(1) 生成AI活用のためのデータガバナンス(非技術論の観点からの課題)
(2) データ品質(求められる出力データの品質)
(3) データ基盤の全体像、データの管理
(4) 散在する既存データの活用のあり方
(5) 生成AI活用のための構造化データ、非構造化データの整備のあり方
(6) データ整備の進め方
【論点2】 業務プロセスの可視化、データ基盤の整備ができていない企業については、 生成AIを使ってデータ基盤を簡単に作る手段を考える。
(1) 生成AIを活用したデータ整備(構造化)に関する取組課題
(2) 具体的な応用事例
3. 生成AIによるデータ利用技術および海外の産業界・政府の取組の動向
生成AIによるデータ活用技術の最近の研究開発動向や各国政府・産業界の動向について紹介する。
[1] データスペース
各国が独自の法律や規制を持つ欧州では、国境を越えて情報を共有する際の問題を解決する必要があるため、相互運用性を担保する共通の仕様に基づいてデータを連携・共有する「データスペース」の整備・運用が、早くから進められている。
データスペースとは、異なる組織やプラットフォーム間でデータを安全に共有するための仮想的な共有空間を指す。データスペースは、データを持つ各組織が自身のデータを自身の環境で管理しつつ、許可されたパートナーとデータを共有できる仕組みである。ここでは、データ所有者は自分のデータを自分の手元に保持しながら、他の組織と安全に情報を共有できる(図2参照)。
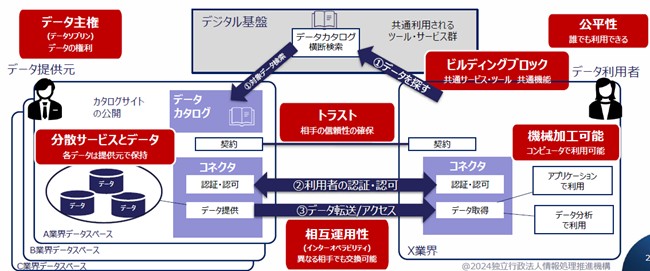
【出典】 IPA提供資料
データスペースは、データの所有者がデータの利用を細かくコントロールできる一方で、データの利用者は必要なデータを効率的に取得できるという、双方にとってのメリットを持つ新たなデータ共有の方法である。欧州においては、各国が独自の法律や規制を持つ中で、データスペースがデータ交換の新たなスタンダードとなりつつある。
[2] オントロジー
オントロジーとは、知識工学の分野で使われる概念の一つであり、物事の本質やその関係性を体系的に整理したものを指す。簡単に言えば、特定の分野やテーマに関する知識を「どんな要素があり、それらがどう関係しているのか」という形で構造化したものである。
欧州の製造企業では、特に、標準化やインターオペラビリティ(システム間の相互運用性)を重視する企業文化を背景として、オントロジーのような体系的な知識モデルを積極的に採用する傾向が比較的強い(例:独Industry4.0の取組)。一方、日本の製造企業では、現場の具体的な実務や成果に直結する技術が優先され、オントロジーのような抽象的で長期的な視点を必要とする考え方の導入が欧州ほど進んでいないケースがあると思われる。
しかしながら、製造業のデジタル化が進むにつれて、オントロジーの重要性は今後、地域を問わず、更に高まるものと考えられる。
[3] Retrieval-Augmented Generation (RAG)
クラウドサービスなどで提供されている生成AIに、企業組織などが独自に保有しているデータを組み合わせて活用するための仕組みとしてRAGと呼ばれる方式が注目されている。RAGでは、まず企業が社内外から入手し独自に持つ文書(外部文書)を一定サイズの大きさにぶつ切りにし、データベースに取り込んでおく。この取り込んだデータベースとユーザーの質問文との間で類似度検索を行い、類似度の高いデータを取り出し、これをもとに生成AIに問い合わせ、回答を生成する。企業独自のデータや最新の外部データを取り込むことで、ユーザー企業が自社でより有用な回答を生成AIから得やすくなる効果がある。
ただし、外部文書の中から類似度の高いものをデータベースから抜き出すため、質問の回答に無関係な情報を使って生成AIに問い合わせることもある。また、外部文書がぶつ切りにされるため、本来欲しいデータに加えて関連性の低いデータも一緒に抜き出されることがある。このため、必ず欲しい回答となるわけではない点に留意する必要がある。
[4] 欧州製造関連データスペースの現状
欧州ではCatena-X(カテナ-X)やMARKET4.0、Smart Connected Supplier Networkなど、データの相互運用性に向けたデータ基盤の整備、集約が非常に進んでいる状況にある。特に欧州では知識グラフの産業に関する研究発表も非常に多くあるが、すべてこのような知識基盤の上での事例を対象にしている。
(欧州の事例)Catena-X
Catena-Xは、2021年にドイツのBMWグループとメルセデス・ベンツが中心となり設立し、自動車業界向けのデータ共有エコシステムである。このエコシステムには、自動車メーカーや部品メーカー、ディーラー、ITベンダー、研究機関など、さまざまなプレイヤーが参加しており、これら自動車のバリューチェーン全体でデータを共有し、効率化や最適化、競争力の強化、そして持続可能なCO2排出量削減を目指している。
Catena-Xの参加メンバーは、データの透明性と信頼性を確保し、サプライチェーン全体での協力を促進するために、必要なデータを提供し、共有する義務があるとされている。具体的には、参加メンバーは、製品のライフサイクル全体にわたるCO2排出量を計算し報告する義務、サプライチェーン全体で必要なデータを共有する義務を有する(出典:Catena-X「Product Carbon Footprint Rulebook」)。
これらの規定は、参加メンバー外には直接的な効力を有するものではないが、取引条件として設定されることが多いため、今後、実質的には広範な影響力を持つ可能性も想定される。
[5] 英国政府の取組
データ活用に向けては、対象とする企業規模および産業別での「データマチュリティ 」(データ活用の総合的な成熟度)の程度と生成AIの使用規模や実用化に向けての進捗がバランスをとって進んでいくことが望ましい。生成AI活用を成功させるために、データマチュリティのレベルを上げることが有効であるともいえる。
組織的なデータ活用の総合力であるデータマチュリティを評価するための指標としては、英国政府のData Maturity Assessment for Government が例として挙げられる。これは、元々民間向けだったデータマチュリティ診断を政府組織にも適用できるように変更したものである。わかりやすいトピックとテーマで構造化されており、引き続き民間企業においても参考にできる。このアセスメントは、初期のゴール、データマチュリティとは何か、データマチュリティの利点や効果、アセスメントの計画等を理解し、総合力向上のきっかけを作るために活用できる。
4. 企業内データ基盤の検討に当たってのデータモデル
本フォーラムでは、データ基盤を3レイヤーに分けて、それぞれについての課題と論点を整理することとした。
3レイヤーについての具体的な説明は、以下のとおりである。
① オリジナルデータ: システムやセンサー、人により生成される生データ、一次データを言う。
② 既存データ基盤: オリジナルデータを様々なデータ活用ニーズに応じて提供可能とするため、データ収集・蓄積しユーザーに提供するための仕組み。また、それらデータを分析するためのBI(Business Intelligence)ツール を含む場合もある。
③ 生成AIデータ基盤:生成AIの回答を出力するために使われるデータを収集・蓄積し生成AIシステムに提供するための仕組み。
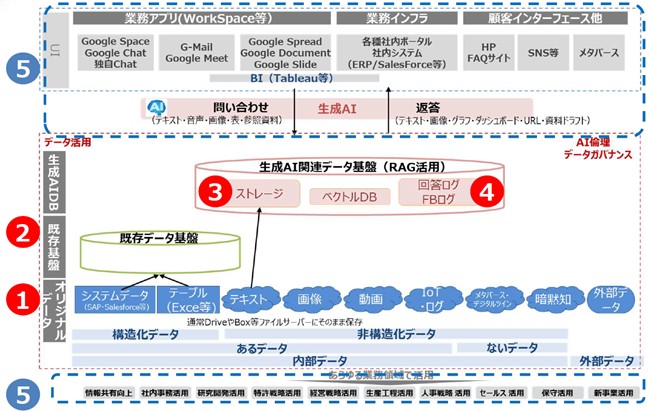
❶オリジナルデータ:システムやBOX・Driveなどに保管されている
❷既存データ基盤(進んでいいる企業は整備されている)
❸生成AIに読み込ませるデータ(クラウド内等に保管する)
❹生成AIから出力されるデータ(クラウド内に保管、チャットの回答・そのまま後続処理に渡される)
【図3】 3レイヤー構成のデータ活用基盤
【出典】 第1回 フォーラム資料より抜粋
5. 現在のデータ基盤における問題点 【論点1】
~ 業務プロセスの可視化やデータ基盤の整備が進んでいる企業が生成AIを積極導入する上で抱えているデータ基盤の問題点 ~
[1] 生成AI活用のためのデータガバナンス(非技術論の観点からの課題)
社内横断的なデータ共有や活用には部門間の「カベ」が障壁となりやすい。これを打破するためには経営トップの積極的かつ継続的な関与が必要なのである。そのためデータ活用のガバナンス ・統制はまさに経営トップのリードが必要な領域である。
[2] データ品質(求められる出力データの品質)
① オリジナルデータの品質
オリジナルデータの品質を評価するにあたっては、データ基盤に入れるデータが、具体的にどのような性質・形状のものなのかという点を明確にすることがまず求められる。うまく生成AIを活用するためには、自社が持つデータの種別やフォーマット形式の分類を具体的に行い、その種別・形式ひとつひとつについて、どのようなデータが取り出せるのかを検討することを初めめに行うのが望ましい。
② 生成AIの回答品質
回答品質の要求レベルについて、そもそも現在できている品質レベルがどの辺にあるか、それに対して、求める品質のレベルがどこにあるかによって、必要な対応が変わってくる。
また、要求する品質レベルを得るために必要なすべてのデータを整備するところから始めると最初が大変となるため、まず、現状のデータを使用して、一度使ってみて、問題があればオリジナルデータの改善に取り組むといったステップを踏むことが現実的であると考えられる。
[3] データ基盤の全体像、データの管理
生成AI活用に向けたデータ基盤の最適解は、ユースケースや使用するアプリケーションごとに異なるが、活用を進める企業においては、「生成AIデータ基盤」の構築・運用に当たって、以下のような問題点への対応が求められる。
① データへのアクセス制限の設定機能と設定の考え方の必要性
② 語彙・用語の統一
③ データの増大への対応
[4] 散在する既存データの活用のあり方
生成AIの活用という観点からは、どのような方法であっても、必要なデータにアクセスできる点が担保されれば、生成AIでのデータ活用が可能となる。この考えに立てば、どんなプラットフォームを使ったら良いかとか、基盤のあり方、選択は気にしなくても良くなる。
また、散在するデータの中には低品質なデータや古いデータも存在する。これらを生成AIデータ基盤に取り込むことは、かえって生成AIの回答品質に悪影響を及ぼす危険性があるため、古いデータをコストをかけてまで生成AIデータ基盤に取り込む必要があるかどうかは検討が必要である。
[5] 生成AI活用のための構造化データ、非構造化データの整備のあり方
データの構造化に関しては、非構造化データを一旦構造化した方がデータの活用時には検索性がよいが、非構造化データを構造化するのはコストパフォーマンスが悪い。どこまで整備を行うかは、どこまで何をやりたいかによる。このため、すべての非構造化データを完全な形で構造化する必要はない。
活用目的や生成AIによる回答結果に求める信頼性の度合いによっては、オリジナルデータにある程度タグ付けを行う、いわば半構造化 まで行ったり、知識グラフなどを持たせたりする等が有効な場合もありうる。
[6] データ整備の進め方
① 生成AI活用の狙い、データ基盤構築のゴールの明確化の必要性
企業として何のために生成AIを活用したいのか、どのように使いたいのかという点を、はじめに整理し、まとめておく必要がある。その際、現状の社内データの整備状況やデータ品質の現状を把握し、生成AIの導入目的に要求されるデータ品質のレベルがどの程度なのか、どれほどの改善が必要なのかという点をしっかり把握する必要がある。
直近のコスト削減を目標として取り組む一方で、生成AIによるデータ活用の新たな適用先を開拓するような活用策を検討し、目標として設定することも必要である。その設定された目標に応じてデータ整備のゴールを設定することが求められる。
② 段階的なデータ整備の考え方と優先順位付けの課題
データ整備に当たっては、まず問題点の全体像を明らかにし、その中から優先順位付けし取り組むべきである。全体を一度に取り組むのではなく、構造化して部分的に実行していく。優先順位付けにおいては、生成AI導入に対して現状のデータ基盤の問題点を列挙し、解決の困難度と導入の効果を2軸でマッピングすることにより整理しやすくなる。
6. 生成AIを活用したデータ整備(構造化) 【論点2】
~ 業務プロセスの可視化やデータ基盤の整備に着手していない企業が生成AIを用いてデータ基盤の構築を進めるための方策 ~
生成AIによりデータ活用を行いたいと考えても、そのためのデータが未整備である企業もあり、特に大企業に比べ中小企業においてはデータ基盤も未整備である企業が多いと考えられる。生成AIは、そのようなデータ基盤整備が未着手である中小企業を始め、大企業においても、データ整備そのものにも活用できる可能性を十分持っている。
生成AI技術の進展により、非構造型のデータをある程度扱えるようになっている。フォーマットが統一されていないフリーテキストの場合、ある程度情報が欠落していても、生成AIが持つ知識で補える可能性もある。
生成AIを使ってどんなデータを作りたいのか、欲しいデータをいかに楽にAIで整備させるのかに関して、例えば、「こんなデータを使って、こんな技術を使った後、こんなメリットがあります」、あるいは、辞書を作りたいなど、具体的な事例で考える必要がある。
今後、生成AIによる企業内データの更なる活用によって、欧米の企業にみられるような新規事業や新サービスの開発といった事業の発展、価値づくりにつながることを期待したい。
また、AIがどれだけ発展しても、その活用や意思決定が人間にとって透明で説明可能でなければ、AIの信頼性や受容性は損なわれる可能性が高い。人間中心のアプローチを維持しつつ、AIの能力を最大限に活用するためのデータ設計は、企業や社会全体で取り組むべき課題である。
7. お問い合わせ先
(一財)機械システム振興協会
なお、本報告書(全文)の印刷物(冊子)のご送付をご希望の方は、本サイトの CONTACT ページの登録サイトからお申し込みください。【本報告書をご希望される方には、無料でご送付いたします。(※国内限り)】